在前一篇文章中提到过,CPython由于实现上的缺陷导致了其对CPU繁忙型任务支持有限,不过Python提供了一种解决方案——多进程,多进程方式通过给每个进程启动一个单独的解释器来避免了GIL问题。
多进程
多进程提供了两种使用方式:
import multiprocessing
import os
def worker():
print("Current process pid is {}".format(os.getpid()))
class MyProcess(multiprocessing.Process):
def __init__(self, address):
super().__init__()
self.address = address
def run(self):
print("Current process pid is {}, address {}".format(os.getpid(), self.address))
if __name__ == '__main__':
print("Main process pid is {}".format(os.getpid()))
p1 = multiprocessing.Process(target=worker)
p1.start()
p2 = MyProcess(address='beijing')
p2.start()
p1.join()
p2.join()
启动方式
multiprocessing支持3种方式启动进程,分别是fork、spawn、forkserver,可通过如下方法查看、设置:
import multiprocessing
multiprocessing.get_all_start_methods()
multiprocessing.get_start_method()
multiprocessing.set_start_method('fork')
IPC
PIPE
管道,有单向、先进先出、无结构字节流特点,读写端可以同时进行,父子之间继承关系:
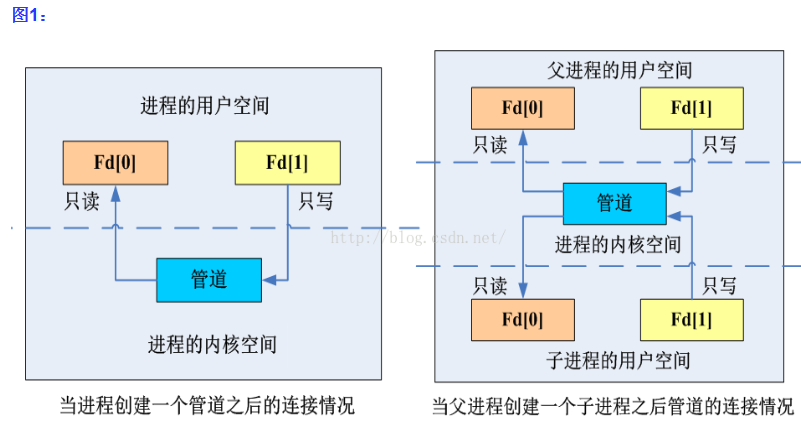
父进程fork出子进程后,子进程继承了父进程的资源(包括文件描述符等),父子进程确定了管道的传输方向后,通常情况下需关闭无用的文件描述符:
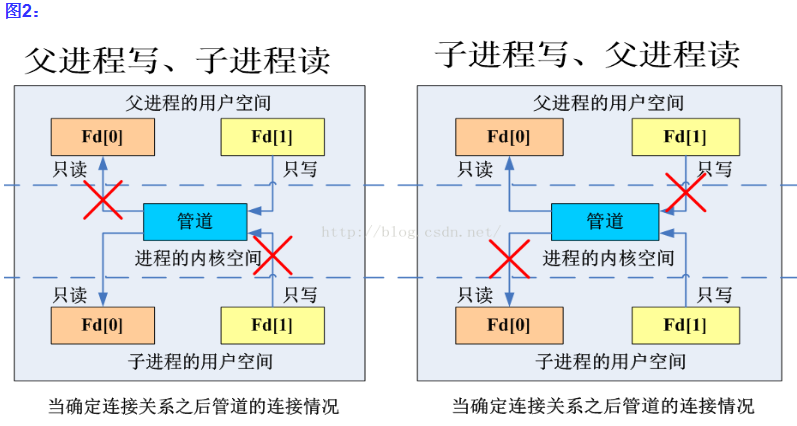
Pipe使用例子:
from multiprocessing import Process, Pipe
def f(conn):
conn.send([42, None, 'hello'])
conn.close()
if __name__ == '__main__':
reader, writer = Pipe()
p = Process(target=f, args=(writer,))
p.start()
print(reader.recv()) # prints "[42, None, 'hello']"
p.join()
Pipe使用有两个地方需要特别注意:
- 通过send方法发送的对象,必须是可pickable
- Pipe非线程或进程安全,但可同时读写
队列
标准库提供了3种进程安全的队列,分别是SimpleQueue、JoinableQueue、Queue,其内部都是基于Pipe实现,使用例子:
import multiprocessing
def worker(enqueue, sentinel=None):
for item in iter(enqueue.get, sentinel):
print("Receive item {}".format(item))
enqueue.task_done()
if __name__ == '__main__':
broker = multiprocessing.JoinableQueue()
p = multiprocessing.Process(target=worker, args=(broker, ))
p.start()
# simulate create tasks
for i in range(10):
broker.put(i)
broker.join()
broker.put(None)
p.join()
Pool
通常情况下需要利用进程池来避免进程创建、销毁开销,同样地,标准库提供了进程池供开发者使用:
import multiprocessing
def square(x):
return x ** 2
cpu_cores = multiprocessing.cpu_count()
with multiprocessing.Pool(processes=cpu_cores) as pool:
result = pool.map(square, range(10))
print(result)
result = pool.apply(square, args=(10,))
print(result)
result = pool.apply_async(square, args=(100,))
print(result.get())
Pool提供的API可分为三类:同步、异步、MapReduce,关于MapReduce的API,有个细节需要注意:标准库并没有做容错性处理,也就是说如果Map出去的某个chunk出了问题导致其结果没有传回,同步调用的方式会导致主进程死等,所以比较好的调用方式是通过异步和超时控制:
import multiprocessing
def square(x):
return x ** 2
cpu_cores = multiprocessing.cpu_count()
with multiprocessing.Pool(processes=cpu_cores) as pool:
async_result = pool.map_async(square, range(100), chunksize=10)
try:
result = async_result.get(timeout=2)
print(result)
except multiprocessing.TimeoutError:
print("Fetch result got timeout.")
共享状态
multiprocessing提供的共享状态有两种方式:共享内存、服务器进程。
共享内存
主要通过Value或Array实现:
from multiprocessing import Process, Value, Array
def f(n, a):
n.value = 3.1415927
for i in range(len(a)):
a[i] = -a[i]
if __name__ == '__main__':
num = Value('d', 0.0)
arr = Array('i', range(10))
p = Process(target=f, args=(num, arr))
p.start()
p.join()
print(num.value)
print(arr[:])
输出如下:
3.1415927
[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
Value或Array对象内部默认会有一把可重入锁来同步访问该对象,所以并发情况下对共享对象进行写操作时,需如下操作:
from multiprocessing import Value, Process
def increment_share_state(counter):
with counter.get_lock():
counter.value += 1
share_value = Value('i', 0)
ps = []
for i in range(10):
p = Process(target=increment_share_state, args=(share_value,))
ps.append(p)
for p in ps:
p.start()
for p in ps:
p.join()
print(share_value.value)
同步、互斥
同步与互斥是抽象层概念,其不限于进程、线程、协程,另外,多进程同步、互斥使用方式与threading模块下的同步机制大体类似,这里就不做过多叙述了。
日志
标准库提供了get_logger用于配置multiprocessing模块记录日志,也可通过调用log_to_stderr将日志输出到终端:
import multiprocessing
import logging
def worker():
print("Child Process done.")
multiprocessing.log_to_stderr(logging.DEBUG)
p = multiprocessing.Process(target=worker)
p.start()
p.join()
输出如下:
[INFO/Process-1] child process calling self.run()
Child Process done.
[INFO/Process-1] process shutting down
[DEBUG/Process-1] running all "atexit" finalizers with priority >= 0
[DEBUG/Process-1] running the remaining "atexit" finalizers
[INFO/Process-1] process exiting with exitcode 0
[INFO/MainProcess] process shutting down
[DEBUG/MainProcess] running all "atexit" finalizers with priority >= 0
[DEBUG/MainProcess] running the remaining "atexit" finalizers