复制集
复制集由一组mongod进程组成,通过冗余提升数据可用性,并在主节点不可用情况下提供自动故障转移功能,一个典型的复制集:

复制集通过mongo shell的rs.initiate进行初始化,初始化后各个成员间发送心跳并发起Primary选举,获得大多数成员投票的节点会成为Primary,其余节点成为Secondary。
config = {
_id : "replName",
members : [
{_id : 0, host : "rs1.example.net:27017"},
{_id : 1, host : "rs2.example.net:27017"},
{_id : 2, host : "rs3.example.net:27017"},
]
}
rs.initiate(config)
大多数定义:假设复制集内投票成员为N,则大多数为N/2+1,当复制集内存活成员不及大多数时,整个复制集处于只读状态。
| 投票成员数(N) | 大多数(N/2+1) | 容忍失效数 |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
| 7 | 4 | 3 |
从上图表中可以看出,当N为偶数时,其容忍失效数与N - 1相同,所以一般复制集中投票成员个数往往为奇数
另外,Mongo复制集引入了一种特殊的Secondary节点—Arbiter,Arbiter节点只参与投票,既不能被选举为Primary,也不从Primary同步数据,故而Mongo复制集又存在另外一种部署方式:

Mongo复制集采用异步复制方式,Primary与Secondary之间通过oplog重放来达到数据一致性,Primary节点完成写操作后,会向local.oplog.rs集合写入一条记录,Secondary不断从Primary拉取新的oplog并执行(oplog支持幂等性),可认为主动拉模型。
local.oplog.rs被设置成一个capped集合,概念上可理解为一个环形队列,集合的大小会影响Seondary做全量同步还是部分同步问题,需根据业务量调整集合大小。
默认情况下,复制集所有的读请求都发到Primary,Driver可通过设置Read Preference来将读请求路由到其他节点。
- primary:默认配置,所有读请求转发到Primary
- primaryPreferred:Primary优先,若Primary不可达,请求Secondary
- secondary:所有读请求都转发到secondary
- secondaryPreferred:Secondary优先,当所有Secondary不可达时,请求Primary
- nearest:读请求发送到最近的可达节点(通过ping探测出最近节点)
Mongo复制集关于写操作,引入了一个概念—Write Concern,默认情况下,Primary写完即返回给客户端,Driver可通过设置Write Concern来配置写成功规则。
journal是Mongo存储引擎层的一个概念,MongoDB支持的存储引擎都支持配置journal,MongoDB所有数据的写入、读取都是通过调用存储引擎层的接口来实现,journal是存储引擎存储数据时的一种辅助机制。
以wiredtiger为例,如果不配置journal,写入wiredtiger的数据,并不会立即持久化存储,而是每分钟做一次全量checkpoint(频率可配置)将数据持久化;如果中间出现宕机,那么数据只能恢复到最近一次的checkpoint,这样会存在丢失一分钟数据的可能。
开启journal后,每次写入会记录一条操作日志,这样即使出现宕机后,启动时wiredtiger会先将数据恢复到最近一次checkpoint,然后重放后续的journal操作日志来恢复数据。
journal行为主要由两个参数控制:storage.journal.enabled、storage.mmapv1.journal.commitIntervalMs,前者控制是否开启journal,后者控制journal刷盘时间,默认为100ms,用户也可以在写入时指定writeConcern为{j:true}来每次写入时都确保journal刷盘。
关于MongoDB配置选项,可参考官方提供的完整配置说明,读者可自行搭建复制集测试。
分片
MongoDB分片集群由如下组件组成:
- mongos: 提供路由功能,在应用程序和分片集群间提供接口
- config servers: 存储集群配置信息,一般为一组复制集,俗称CSRS
- shard: 每个分片由一组复制集节点组成
分片集群中各节点间的交互:

分片集群通过mongos管理配置信息,分片添加、移除、分片键等都可在mongos shell下配置。
MongoDB以collection为单位做数据分片,通过分片键将数据分布到多个分片下。
mongos中涉及到的一些命令:
# 添加分片
sh.addShard("sh0/192.168.6.50:27010,192.168.6.51:27011,192.168.6.52:27012")
# 对test数据库启用分片
sh.enableSharding("test")
# 对某集合进行分片
sh.shardCollection("test.person", {"identity": 1, "name": 1})
需要注意的是,MongoDB中需要对数据库启用分片后,才能对集合进行分片设置。
关于分片,这里主要想谈下shard key,其作用在于分片策略会根据其值将数据分布到各个shard上。
shard key可理解为针对一条document提取一个索引,在对集合分片配置时指定,如:
sh.shardCollection("test.person", {"identity": 1, "name": 1})
分片策略根据shard key将数据划分到不同的chunk,chunk存放在各个shard上。
MongoDB支持的分片策略有两种:范围分片和哈希分片,哈希分片的本质是对shard key通过hash计算后的值进行范围分片,故而这里只讨论范围分片。
范围分片的思想可简述理解为—将数据空间划分为k个互斥的子空间,各个子空间取并集构成原始空间。

上图中,x值域为(-∞,+∞),范围分片后,分成了4个子区间(-∞,-75)、[-75,25)、[25,175)、[175,+∞)
每个区间对应着一个chunk,一个chunk对应某个shard,一个shard上可存储多个chunk,chunk默认情况下阀值大小为64MB,超过阀值后会导致chunk分裂(jumbo chunk例外)
使用范围分片策略,初始情况下,存在一个范围为(-∞,+∞)的chunk,后续数据写入会导致chunk分裂、迁移,整个过程类似下图:
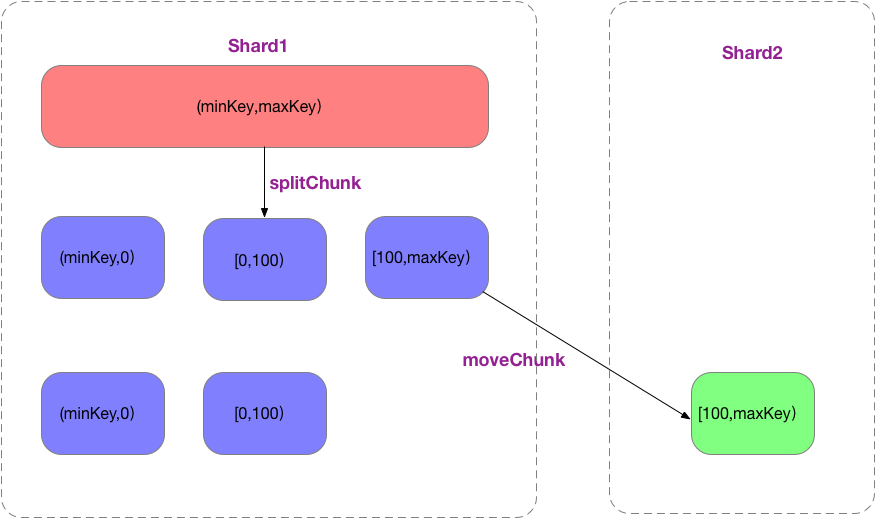
使用哈希分片策略,可通过预分配chunk来减少分裂、迁移开销。
关于如何选择shard key及shard key的好坏性后面有时间在研究研究,暂时就了解这么多了。